ShuffledRDD
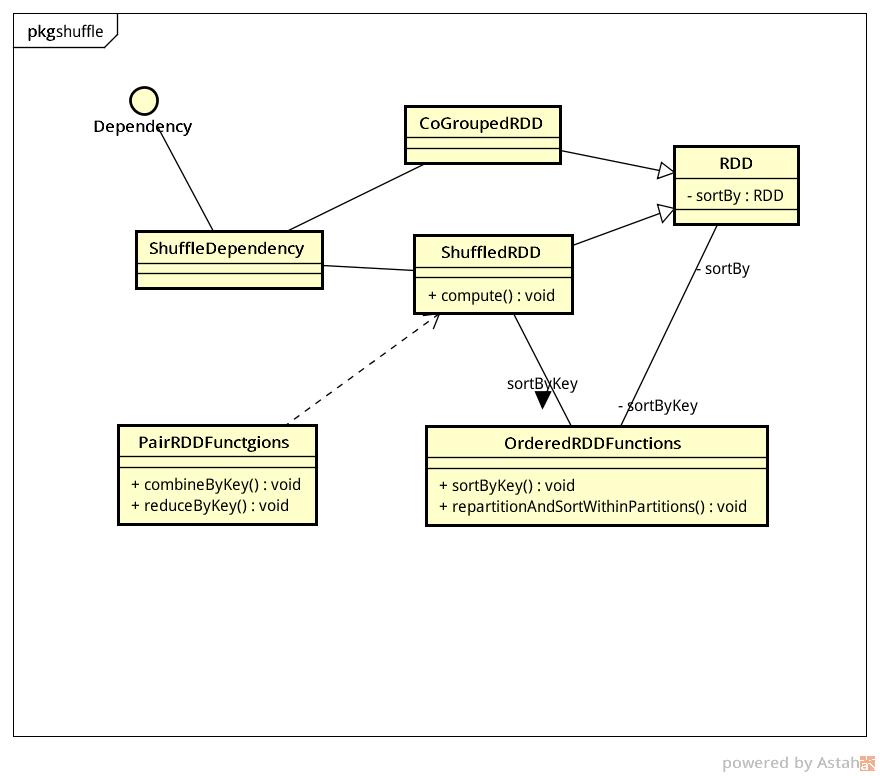
Do what
这时候数据已经经过了shuffle map,这时候的工作是从相同key在一个partition里的数据做aggregation
class ShuffledRDD[K, V, C](
@transient var prev: RDD[_ <: Product2[K, V]],
part: Partitioner)
extends RDD[(K, C)](prev.context, Nil) {
override def getDependencies: Seq[Dependency[_]] = {
//为此RDD产生一个新的shuffleId,并注册一个与此shuffleId相关联的suffleHandle
List(new ShuffleDependency(prev, part, serializer, keyOrdering, aggregator, mapSideCombine))
}
override def getPartitions: Array[Partition] = {
Array.tabulate[Partition](part.numPartitions)(i => new ShuffledRDDPartition(i))
}
override def compute(split: Partition, context: TaskContext): Iterator[(K, C)] = {
val dep = dependencies.head.asInstanceOf[ShuffleDependency[K, V, C]]
//ShuffleRDD前面一定是另一个stage,从磁盘读入前面ShuffleMapTask写出去的数据
SparkEnv.get.shuffleManager.getReader(dep.shuffleHandle, split.index, split.index + 1, context)
.read()
.asInstanceOf[Iterator[(K, C)]]
}
HashShuffleReader
override def read(): Iterator[Product2[K, C]] = {
val ser = Serializer.getSerializer(dep.serializer)
val iter = BlockStoreShuffleFetcher.fetch(handle.shuffleId, startPartition, context, ser)
val aggregatedIter: Iterator[Product2[K, C]] = if (dep.aggregator.isDefined) {
//这里combine的过程aggregator用到AppendOnlyMap或ExternalAppendOnlyMap,参见另一本笔记Spark on Scala
if (dep.mapSideCombine) {
new InterruptibleIterator(context, dep.aggregator.get.combineCombinersByKey(iter, context))
} else {
new InterruptibleIterator(context, dep.aggregator.get.combineValuesByKey(iter, context))
}
}
// Sort the output if there is a sort ordering defined.
dep.keyOrdering match {
case Some(keyOrd: Ordering[K]) =>
// Create an ExternalSorter to sort the data. Note that if spark.shuffle.spill is disabled,
// the ExternalSorter won't spill to disk.
val sorter = new ExternalSorter[K, C, C](ordering = Some(keyOrd), serializer = Some(ser))
sorter.insertAll(aggregatedIter)
context.taskMetrics.memoryBytesSpilled += sorter.memoryBytesSpilled
context.taskMetrics.diskBytesSpilled += sorter.diskBytesSpilled
sorter.iterator
case None =>
aggregatedIter
}
}
private[hash] object BlockStoreShuffleFetcher extends Logging {
def fetch[T](
shuffleId: Int,
reduceId: Int,
context: TaskContext,
serializer: Serializer)
: Iterator[T] =
{
logDebug("Fetching outputs for shuffle %d, reduce %d".format(shuffleId, reduceId))
val blockManager = SparkEnv.get.blockManager
//拿到这个partition(reduceId)数据的Array[(BlockManagerId, Long)],long是数据长度
//比如[(bm1, 234), (bm2, 432)]
val statuses = SparkEnv.get.mapOutputTracker.getServerStatuses(shuffleId, reduceId)
logDebug("Fetching map output location for shuffle %d, reduce %d took %d ms".format(
shuffleId, reduceId, System.currentTimeMillis - startTime))
//statuses按blockManagerId聚集,比如:{(blockManager1,[(0,size)]) (blockManager2, (1, size)) ...},这个index其实就是mapId
//比如生成{(bm1, [(0, 234)]), (bm2, [(1, 432)])}
//似乎不是是数组??
val splitsByAddress = new HashMap[BlockManagerId, ArrayBuffer[(Int, Long)]]
for (((address, size), index) <- statuses.zipWithIndex) {
splitsByAddress.getOrElseUpdate(address, ArrayBuffer()) += ((index, size))
}
//得到对应blockManagerId对应mapId的长度
//比如[(bm1,[(0,234)]),(bm2,[(1,432)])]
val blocksByAddress: Seq[(BlockManagerId, Seq[(BlockId, Long)])] = splitsByAddress.toSeq.map {
case (address, splits) =>
(address, splits.map(s => (ShuffleBlockId(shuffleId, s._1, reduceId), s._2)))
}
//参见下面console的输出
for ((blockMaangerId, seq) <- blocksByAddress){
logDebug(s"hxm: $blockMaangerId, $seq")
}
def unpackBlock(blockPair: (BlockId, Try[Iterator[Any]])) : Iterator[T] = {
val blockId = blockPair._1
val blockOption = blockPair._2
blockOption match {
case Success(block) => {
block.asInstanceOf[Iterator[T]]
}
case Failure(e) => {
blockId match {
case ShuffleBlockId(shufId, mapId, _) =>
val address = statuses(mapId.toInt)._1
throw new FetchFailedException(address, shufId.toInt, mapId.toInt, reduceId, e)
case _ =>
throw new SparkException(
"Failed to get block " + blockId + ", which is not a shuffle block", e)
}
}
}
}
val blockFetcherItr = new ShuffleBlockFetcherIterator(
context,
SparkEnv.get.blockManager.shuffleClient,
blockManager,
blocksByAddress,
serializer,
SparkEnv.get.conf.getLong("spark.reducer.maxMbInFlight", 48) * 1024 * 1024)
val itr = blockFetcherItr.flatMap(unpackBlock)
val completionIter = CompletionIterator[T, Iterator[T]](itr, {
context.taskMetrics.updateShuffleReadMetrics()
})
new InterruptibleIterator[T](context, completionIter)
}
}
16/02/25 11:14:56 DEBUG BlockStoreShuffleFetcher: hxm: BlockManagerId(1, hxm-desktop, 56843), ArrayBuffer((shuffle_0_1_0,18341))
16/02/25 11:14:56 DEBUG BlockStoreShuffleFetcher: hxm: BlockManagerId(0, hxm-desktop, 60758), ArrayBuffer((shuffle_0_0_0,20176))
16/02/25 11:14:56 DEBUG BlockStoreShuffleFetcher: hxm: BlockManagerId(1, hxm-desktop, 56843), ArrayBuffer((shuffle_0_1_1,16674))
16/02/25 11:14:56 DEBUG BlockStoreShuffleFetcher: hxm: BlockManagerId(0, hxm-desktop, 60758), ArrayBuffer((shuffle_0_0_1,20176))
class ShuffleDependency[K, V, C](
@transient _rdd: RDD[_ <: Product2[K, V]],
val partitioner: Partitioner,
val serializer: Option[Serializer] = None,
val keyOrdering: Option[Ordering[K]] = None,
val aggregator: Option[Aggregator[K, V, C]] = None,
val mapSideCombine: Boolean = false)
extends Dependency[Product2[K, V]] {
override def rdd = _rdd.asInstanceOf[RDD[Product2[K, V]]]
val shuffleId: Int = _rdd.context.newShuffleId()
val shuffleHandle: ShuffleHandle = _rdd.context.env.shuffleManager.registerShuffle(
shuffleId, _rdd.partitions.size, this)
}